.HAR file
An HTTP Archive File (.HAR file) is a recorded session of user interaction with an application. The .HAR file keeps all the HTTP requests and responses between the web client and web application.
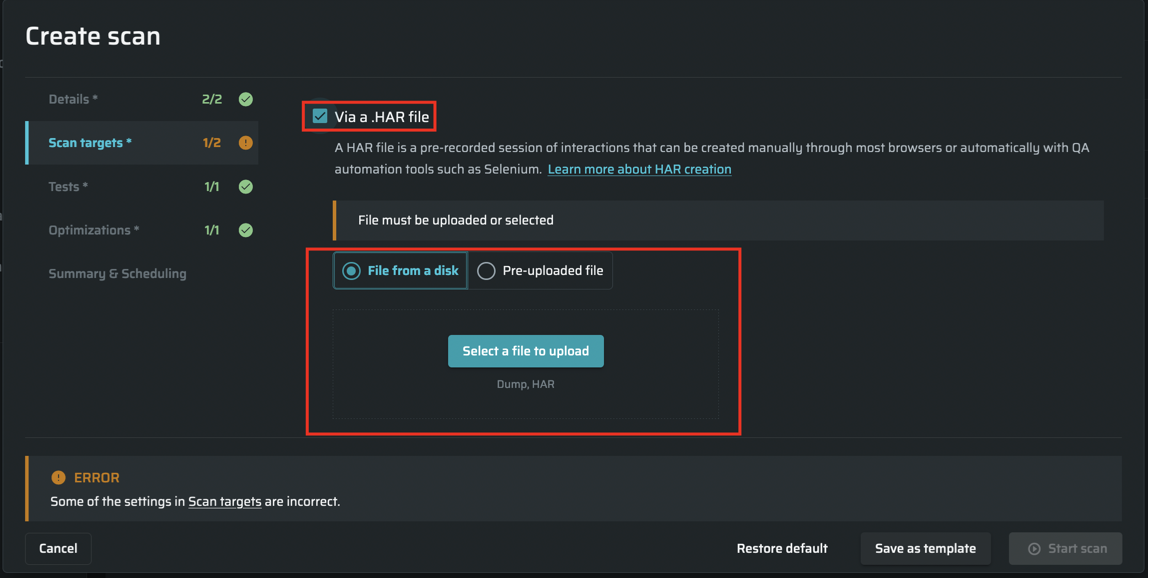
You can use a pre-recorded .HAR file when running a discovery. Using the data contained in the .HAR file, Bright defines the attack surface and ensures complete coverage of the discovery scope. To run a discovery with a .HAR file, in the Recording Session section, you need either to upload a file from a disk or use a file previously uploaded to the Bright storage.
When using third-party QA automation tools, use .HAR format to save session files.
You can create a .HAR file using either specialized tools or common web browsers. See Creating a HAR File to learn how to record an interaction session and review the generated .HAR file.
Important:Authentication coverage - To ensure complete coverage of the discovery, you should configure an authentication object so that the Bright engine can reach the authenticated parts of the target application. See Authentication for detailed information.
HAR upload limits - A single .HAR file is limited to 500 Mb, but you can upload multiple files for larger targets.
| Pros | Cons |
|---|---|
| Deeper coverage. You can enable Bright to switch between the microservers during scanning if the relative data is recorded in the HAR file. Bright uses all the recorded data to define the attack surface. Therefore, it can reach every part of your application covered by the HAR file. | Less automation. You have to create a HAR file on every new part of the application you want to discover. It may be a problem for large development teams where the engagement process is quite complicated. |
| Scope control. The discovery covers exactly the same scope of the target as recorded in the HAR file (determined by a user). Therefore, Bright can run a discovery only for a new part, instead of discovering the whole application on every build. |
Updated 12 months ago