Discovery
Discovery – is a process of finding Entrypoints. This should be made once, since a target is not changed.
Adding Entrypoints to your Project
To start, you will need an entrypoint or a list of them. Bright provides the following methods of finding Entrypoints:
- Crawler - Bright can crawl your web application to define the attack surface. This option does not require any details that might get you tangled. To run a security scan using a crawler, you simply need to specify the target URL in the URL field. Learn more about a Crawler.
- .HAR-file - An HTTP Archive File (.HAR file) is a recorded session of user interaction with an application. The .HAR file keeps all the HTTP requests and responses between the web client and web application.
You can use a pre-recorded .HAR file when running a security scan. Using the data contained in the .HAR file, Bright defines the attack surface and ensures complete coverage of the scan scope. Learn more about .HAR-files in Bright. - API Schema - Bright supports the following versions of the API schemas: Swagger 2+, OpenAPI 3+, Postman 2+. You don't need to have an ideal API-schema, you can upload the one that you have. All you need to do is to fix it once. Learn more about API Schemas.
- Add a single Entrypoint - you can manually add a single Entrypoint using an in-app tool, and then fix it in case if it has connectivity problems. Learn more about how to add fix Entrypoints.
Creating a Discovery
To run a new Discovery in an existing project, follow these steps:
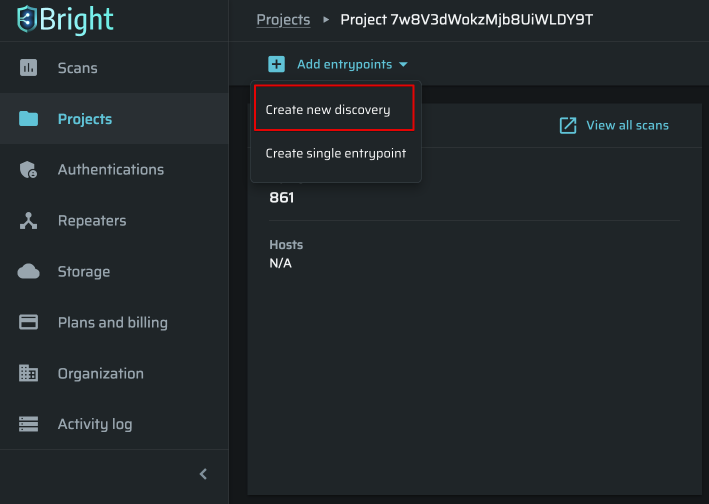
- In the left pane, select the Projects option to see the list of available projects.
- Select the project, then click the Add entrypoints → Create new discovery.
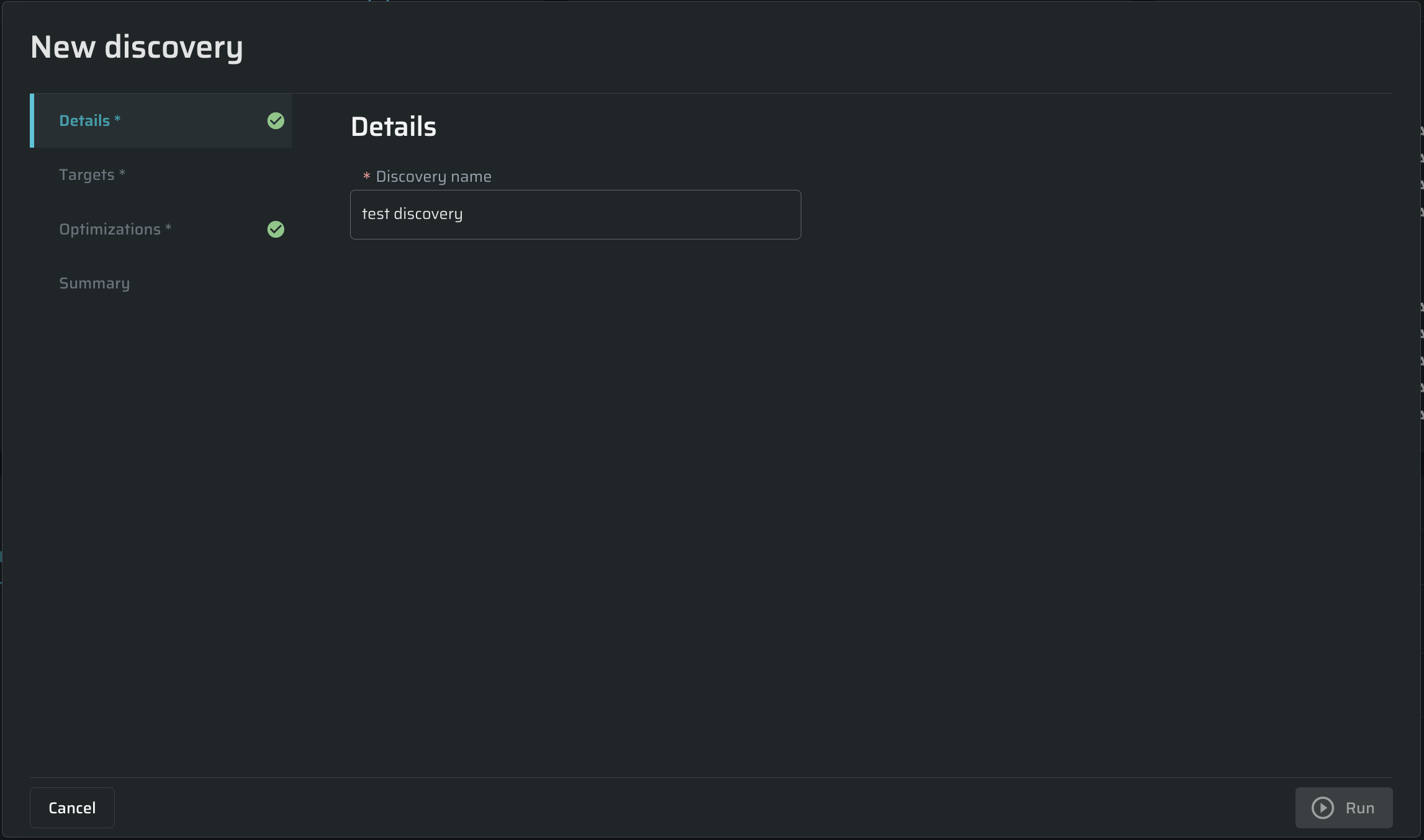
Specifying discovery details
In the Details tab, enter any free-text name for the scan In the Discovery name field.
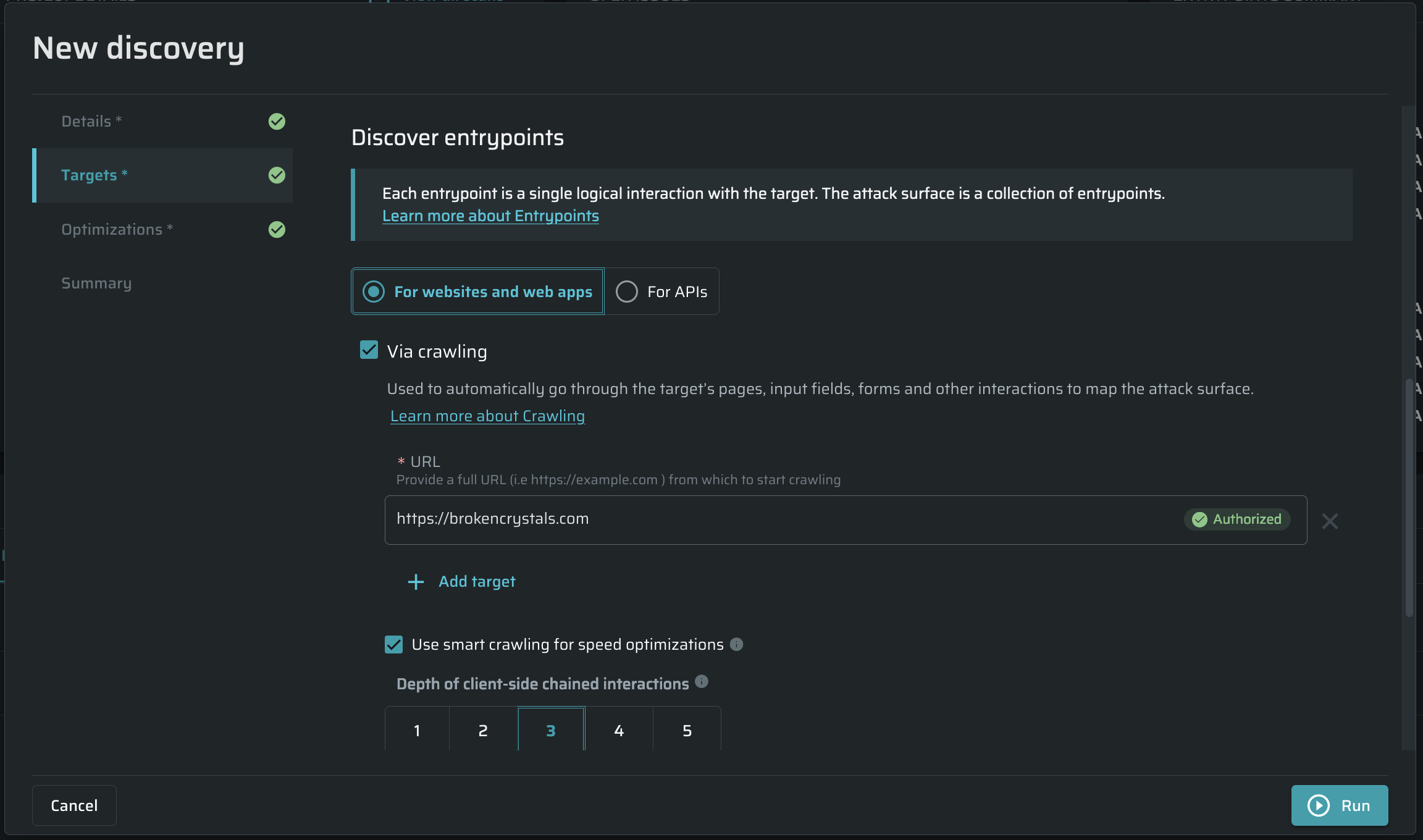
Defining targets
In the Targets tab, do the following:
- Choose a discovery targets type. Discovery targets may be the following types:
Publicly accessible from Bright's cloud - Scanning directly from the cloud is allowed for authorized targets only. Learn more about Target Authorization.
On a private network or not authorized - Scanning via CLI in Repeater Mode, provides secure access to local networks or unauthorized targets. Learn more about Repeater Mode
Target credentials
(Optional) Authentication - Select an authentication type, or Scan without authentication, if it's not needed. Learn more about Authenticated scans.
Discover entry-points
Select a suitable way to discover entrypoints while scanning. Learn more about Entrypoints.
For websites and web apps
Via crawling - Smart Crawler is a procedure aimed to minimize crawler time. It can skip Entrypoints with duplicate parameters, and so on. Learn more about Crawling.
URL - Simply enter a URL (target host) to scan the whole or a part of the specified application. The crawler will map the entire application attack surface automatically.
To discover only specific parts of your application or add multiple hosts, click on the right side of the Targets section. In this case, only the specified sections of the application and everything downstream from them will be scanned.
NoteSome hosts may be unreachable or unauthorized for a direct scan from the cloud:
- If a host cannot be reached by the engine, select a running Repeater for the scan in the Network Settings section.
- If a host is unauthorized for a direct scan from the cloud, either select a running Repeater for the scan or add a
.nexfile to the host root directory. (Learn more about Managing organizations).
Via a .HAR file - Use a pre-recorded session of your interaction with the application (HAR file), which has been created either manually or automatically (using QA tools, such as Selenium to scan your application). This discovery type enables you to define the scope of a scan and ensures complete coverage of the attack surface.
See Creating a HAR File to learn how to create a HAR file.
NoteSome hosts may be unreachable or unauthorized for a direct scan from the cloud:
- If a host cannot be reached by the engine, select a running Repeater for the scan in the section below.
- If a host is unauthorized for a direct scan from the cloud, either select a running Repeater for the scan or add a `.nex file to the host root directory. Learn more about Managing organizations.
See Scanning a website with a HAR file for detailed information.
Delete the file after it has been sent to the engine for a scan - Mark this checkbox if you don't want the file to be saved.
Tip:To enjoy both full automation and deeper attack surface analysis, you can combine Crawling and Recording (HAR) in a single discovery.
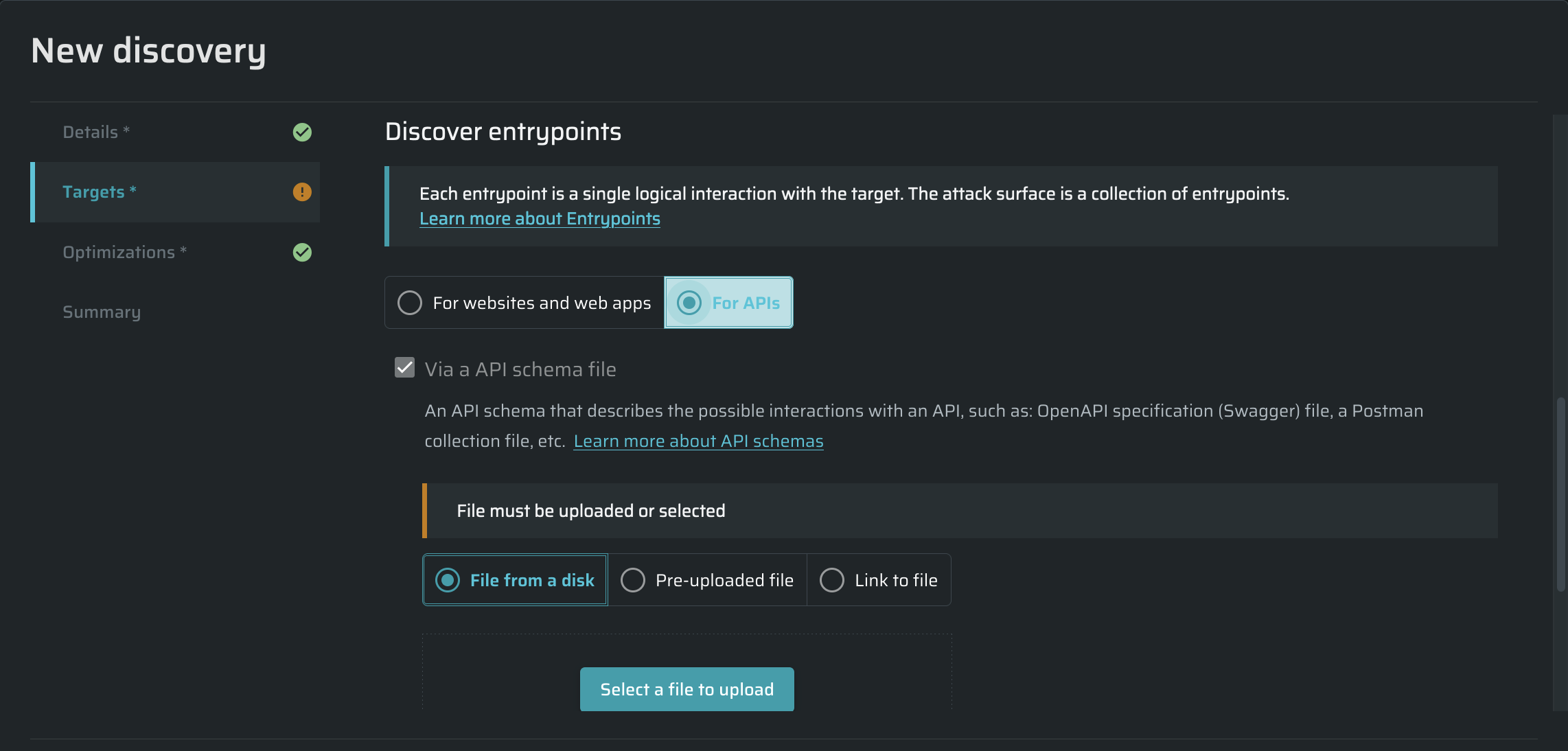
For APIs
Via API schema file (for API endpoints)- Use an *.yml file to discover APIs. See Scanning API endpoints for detailed information. The file can be chosen from a disc or pre-uploaded to the Bright app. Also, you can simply add a link to the file.
Entrypoint discovery options
Skip entry-points, if a response is longer than - Bright allows configuring the limit to entry-point response duration, which is 1000 ms by default. If the response takes longer than the predefined time (for example, due to some target configuration changes), Bright will skip that entrypoint. You can change the limit, but this will affect the scan speed. Learn more about Entrypoints.
(Optional). The Skip Entrypoints by patterns section contains an expression that excludes the most common static files like images, audio, video, and other files that don't contain any vulnerabilities (including fonts). If you don't want these files to be excluded, you can clear the URL regex pattern field.
In this pane, you may set additional parameters to be ignored during scanning.
- Below the Method field, click + Add exclusion . Empty fields will appear.
- From the Method dropdown menu, select the method you want to be excluded from scanning.
- In the URL regex pattern field, enter the parameters for the selected method.
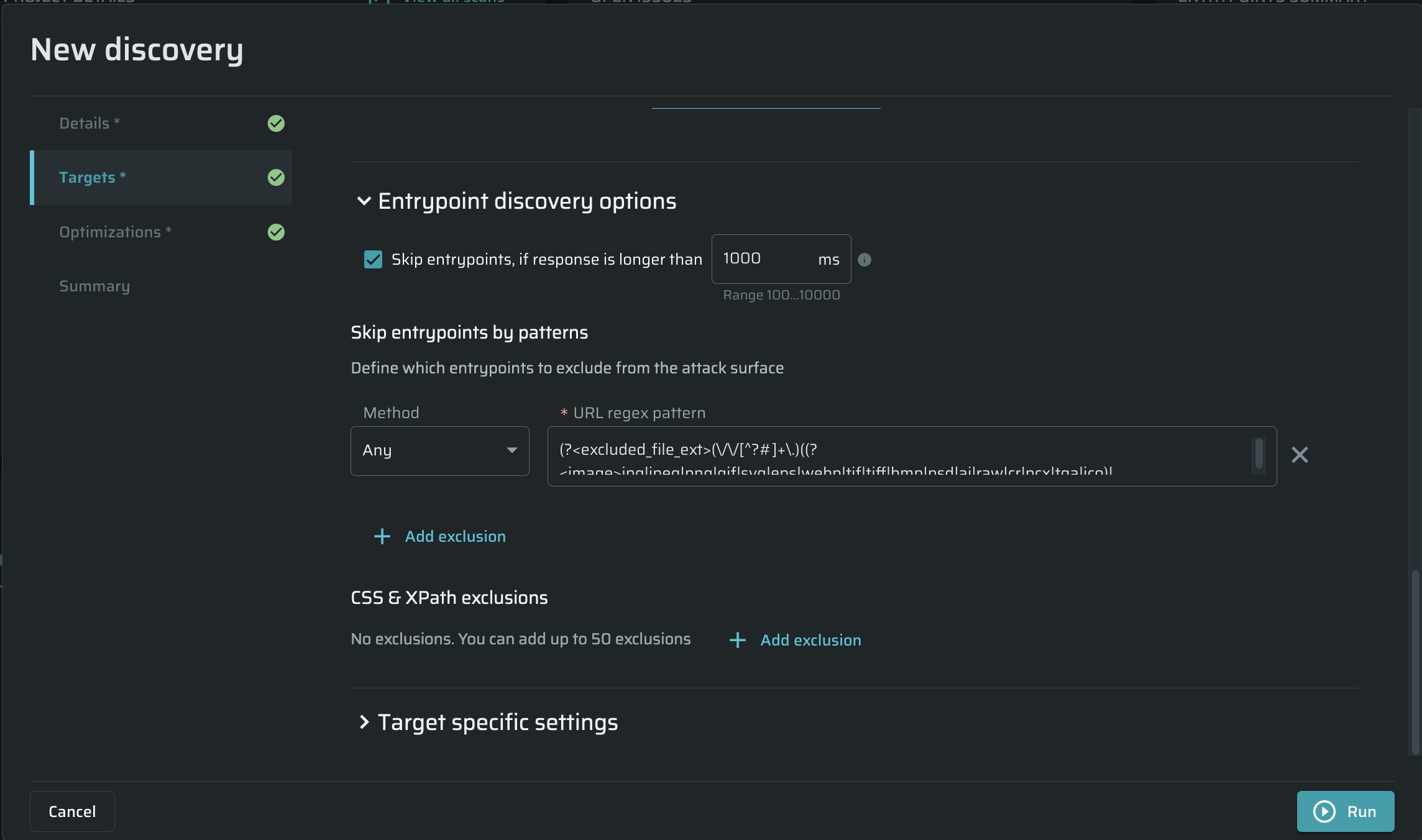
For example, if you don't want the POST method to go over entry points that contain vendor in the URL, from the Method dropdown menu, select POST and then in the URL regex pattern field, enter vendor. Any URL which contains vendor will be excluded from scanning.
CSS & XPath exclusions - CSS selectors & XPath for links to exclude.
Target specific settings
In the Additional Headers section, define any custom headers to be appended to or replaced in each request. If you need to add some authentication headers, see Header Authentication.
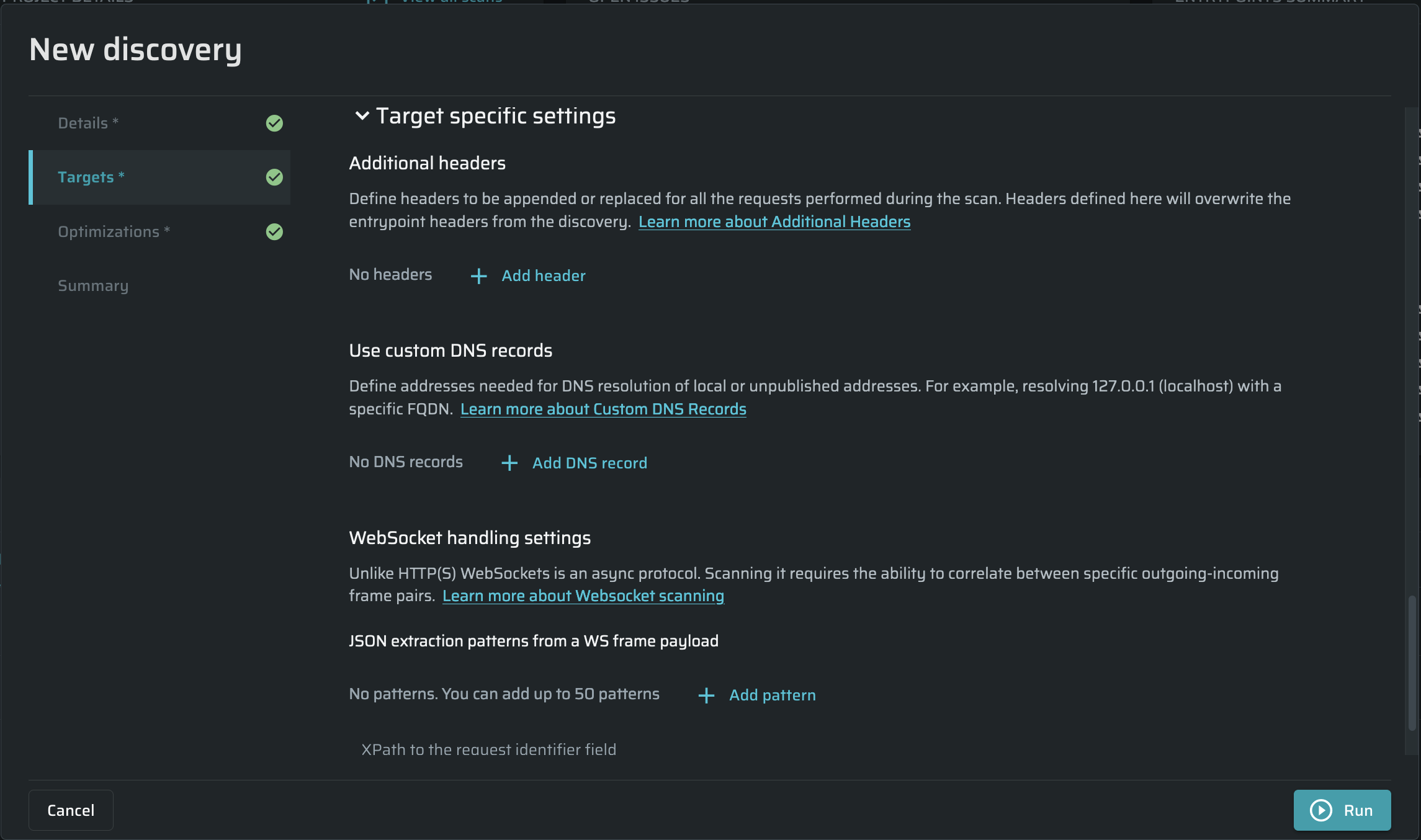
Tip:If you need to add several Additional headers, you can copy-paste them in a single Name field. The headers will be distributed among the fields automatically.
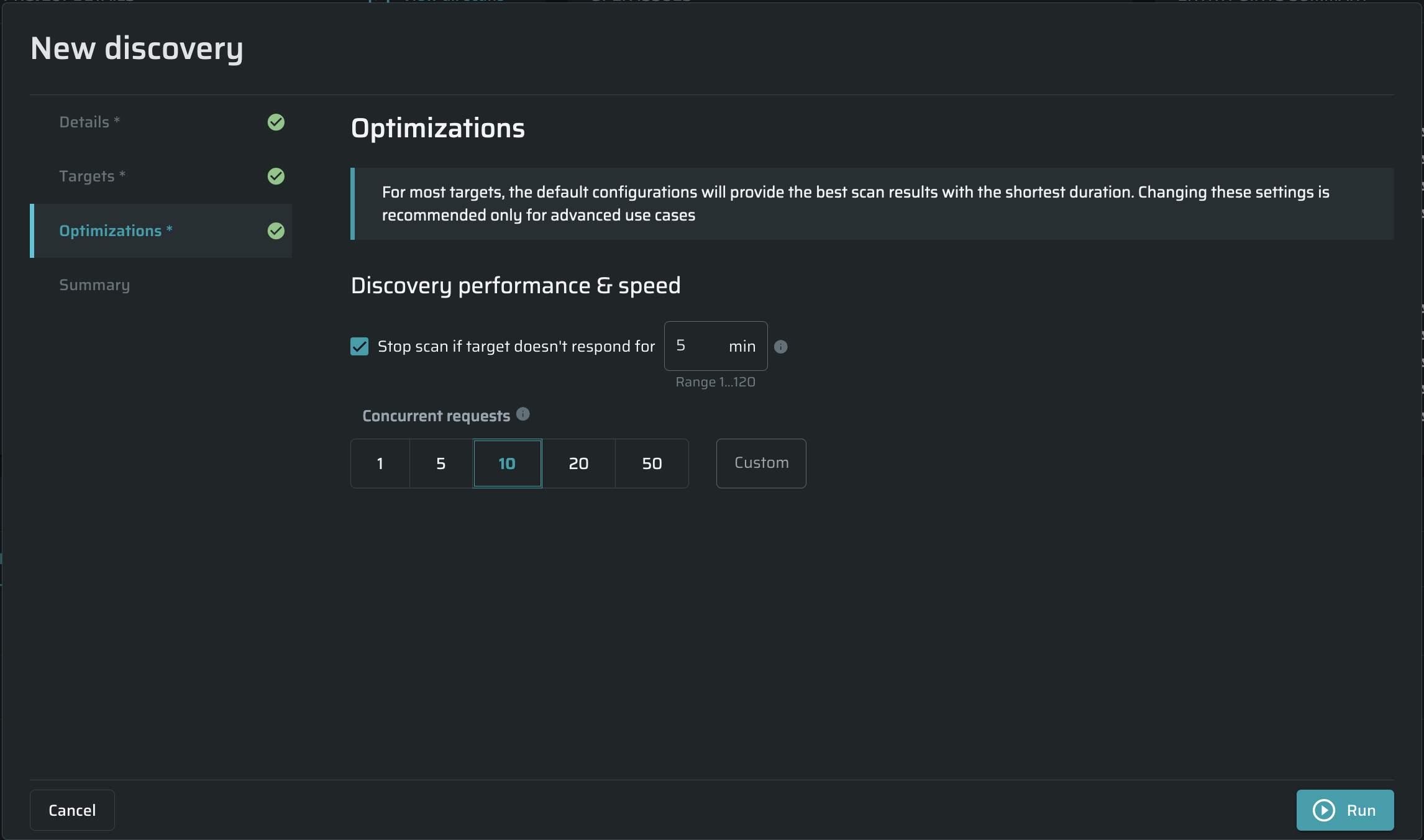
Configuring optimizations settings
Discovery performance and speed
Stop scan, if the target does not respond – Set a limit to response duration for the scan target globally. If the specified duration is exceeded, the scan will be stopped automatically. The default value is 5 min.
Concurrent requests - Specify the maximum concurrent requests allowed to be sent by the scan in order to control the load on your server. The default value is 10 requests.
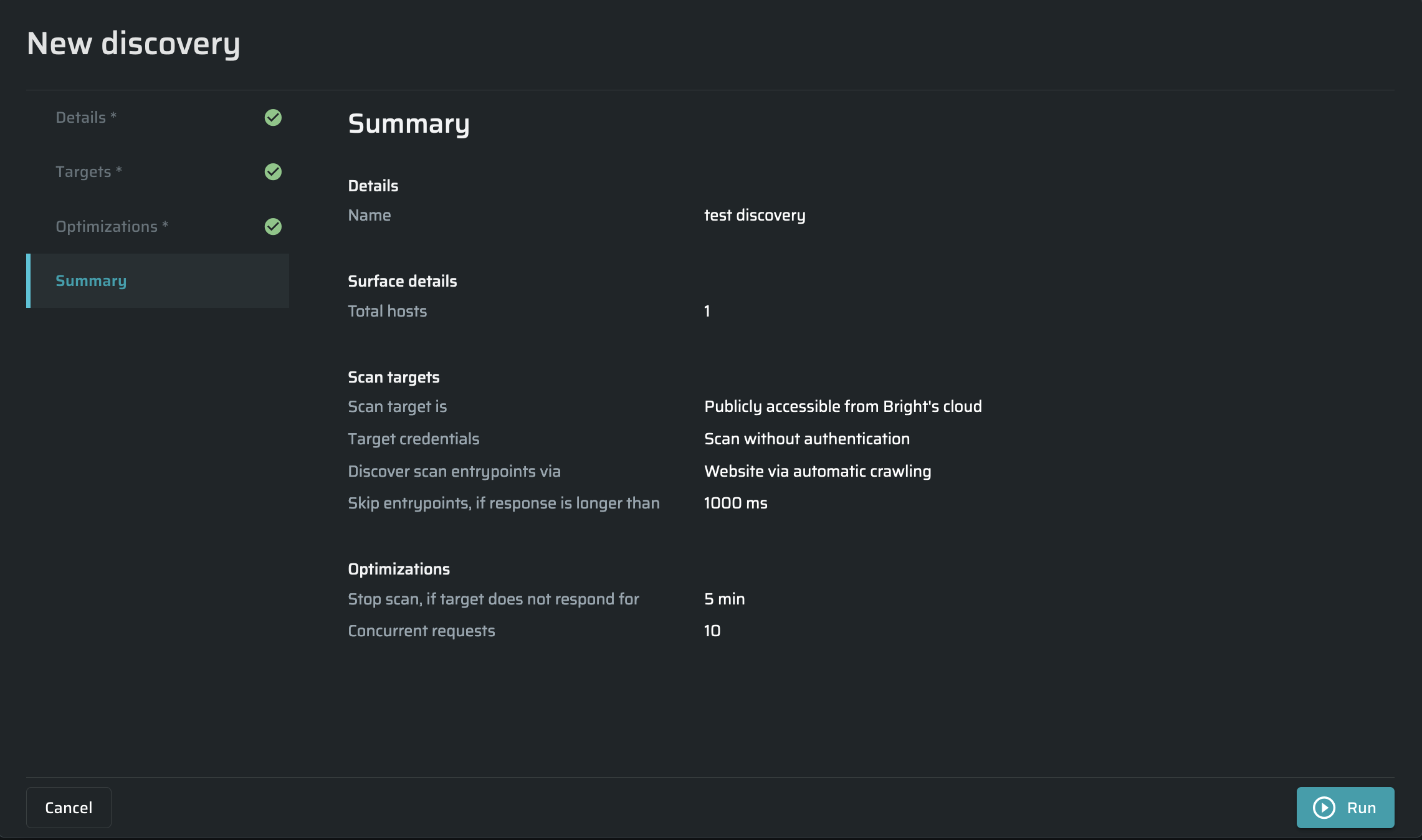
Summary
To start the scan immediately, choose this optionRun.
Creating a Single Entrypoint
Bright provides a user-friendly feature that simplifies the editing of Baseline values. This functionality replaces parsed values with placeholders, making it quick and convenient to modify them. It applies to both dedicated Discovery and the Legacy scan. The Crawler uses the Engine's information to match the Baseline values.
This approach offers the following benefits:
- Comprehensive visibility of the current baseline values and any connectivity issues for each Entrypoint.
- The ability to edit and test Baseline values before initiating scans, ensuring accuracy and efficiency.
- Preservation of optimal baseline values between scans, allowing for consistent and reliable results.
Users have the flexibility to edit these values themselves through the Parameter view. Auto-matched values are labeled as Auto-filled, prompting users to consider modifying the suggested values if needed. When an entrypoint as created manually, all baseline values are automatically categorized as manually added without additional highlighting.
Using this tool you can easily add, edit or fix single entrypoints. If you need to bulk upload, see Creating a New Discovery article.
Adding single entrypoints allows you to fine-tune the scan scope to get optimal coverage. Single entrypoints can be added after a bulk addition to shape a scan coverage.
Learn more about fixing connectivity problems here: Fixing The Entrypoint.
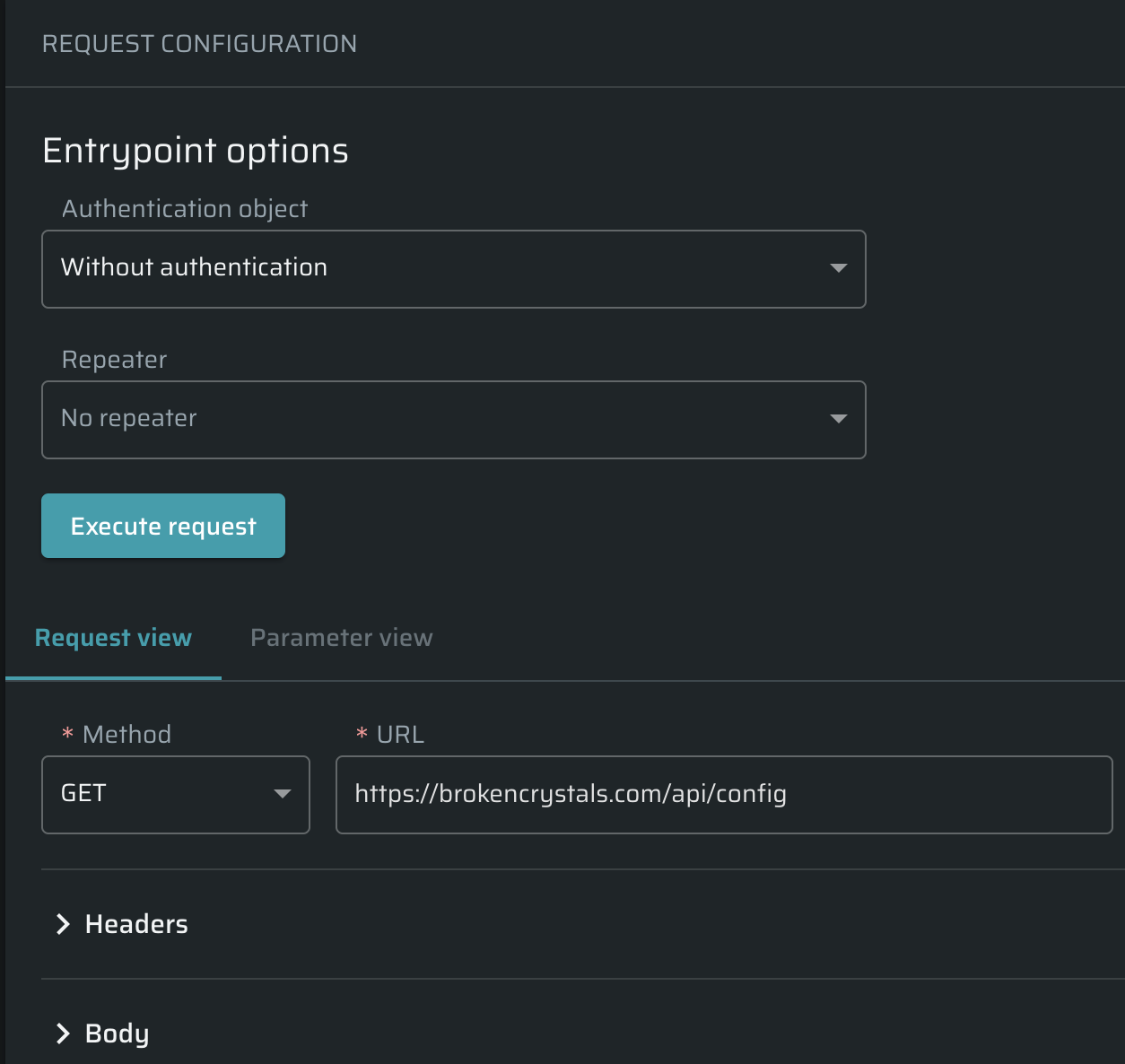
To add a new entrypoint, do the following:
- Open Projects →
 Add entrypoints → Create a single entrypoint.
Add entrypoints → Create a single entrypoint. - Select the authentication object, if available. To learn how to create it, see the article.
- Select a repeater, if needed. To learn how to manage repeaters, see the Repeater (Scan Proxy) article.
- Add the data of the request: Method, URL, Headers, Body.
- Click Execute request to test the entrypoint. Results will appear in the Entrypoint status widget.
- Once the connectivity status is OK, click Create to save changes.
Note:Single entrypoint creation does not create a discovery page
Tracking a Discovery History
To open a table, which contains the detailed information about all performed Discoveries, open:
- Projects tab → select a particular Project → Discovery History
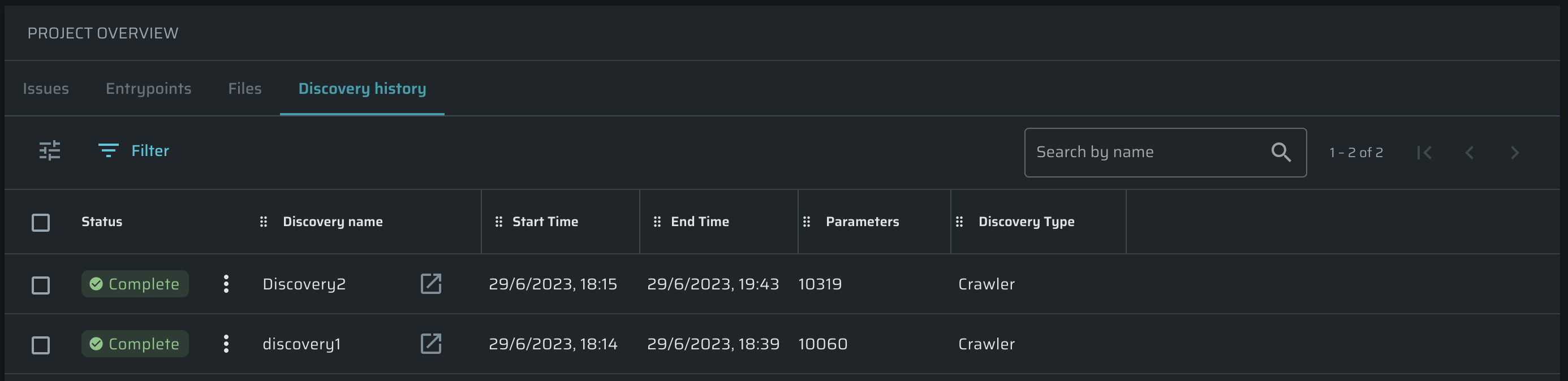
The table is fully adjustable using ![]() icon. Also, you can perform the following actions over Discoveries using
icon. Also, you can perform the following actions over Discoveries using ![]() button:
button:
- Stop
- Rerun
- Delete
To open a Discovery in a separate page, click ![]() button.
button.
Updated about 2 months ago